|
Chaojian Li I am an Assistant Professor in the Department of Computer Science and Engineering (CSE) at the Hong Kong University of Science and Technology (HKUST), where I lead the Sponge Computing Lab. I received my Ph.D. in Computer Science from Georgia Tech in 2025, advised by Prof. Yingyan (Celine) Lin, and my B.Eng. from Tsinghua University in 2019. Email / Google Scholar / LinkedIn / Github |

|
Honors and Awards |
Research InterestsMy research is centered on the intersection of deep learning, computer architecture, and 3D vision. I focus on co-designing systems, architectures, and algorithms to enhance neural rendering and 3D reconstruction, driving advancements in 3D intelligence applications.
|
Selected Publications(*: Equal Contributions; Notable Papers Are Highlighted.) |
|
Uni-Render: A Unified Accelerator for Real-Time Rendering Across Diverse Neural Renderers
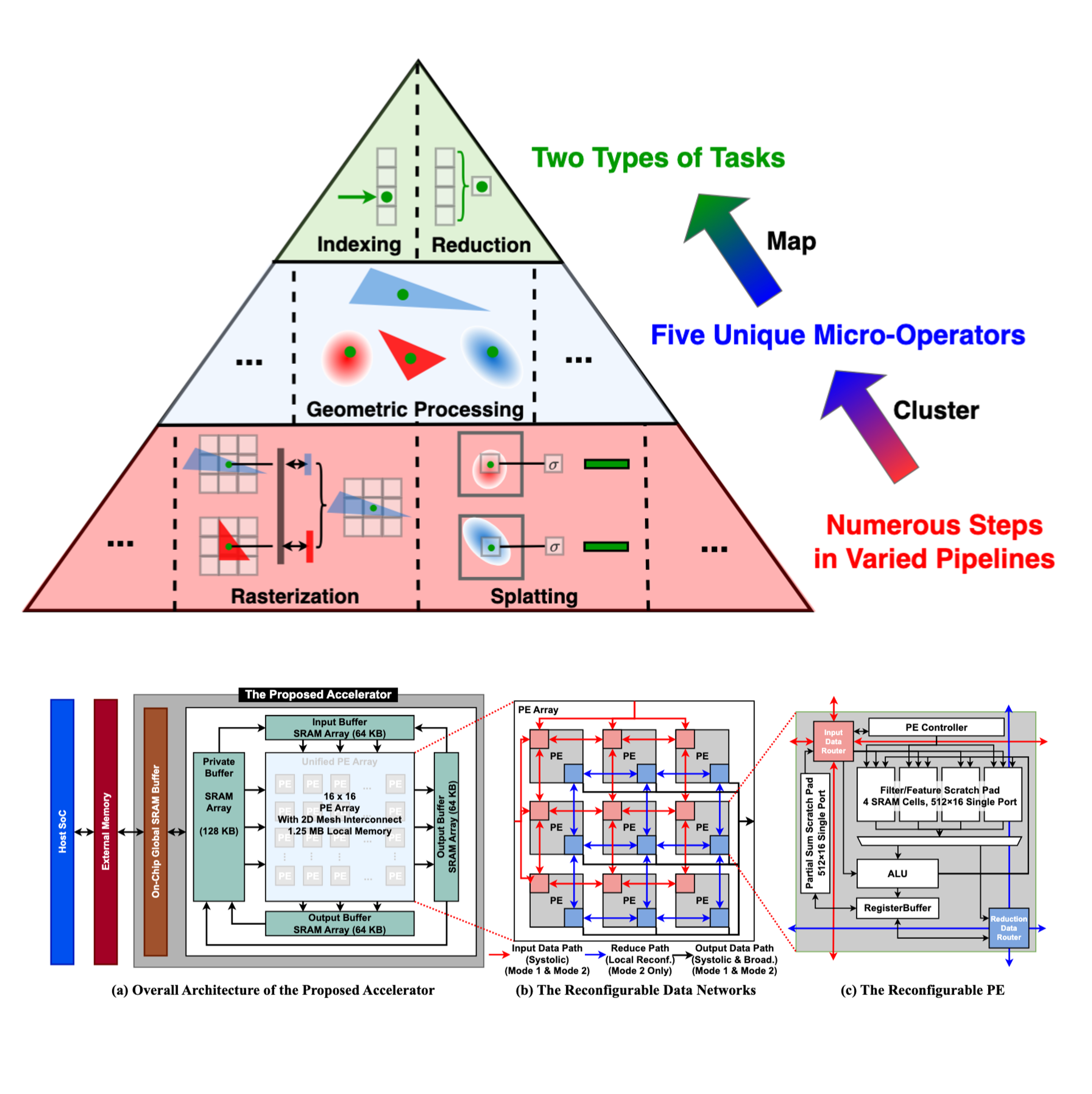
Chaojian Li, Sixu Li, Linrui Jiang, Jingqun Zhang, Yingyan (Celine) Lin HPCA, 2025 A reconfigurable hardware architecture that can dynamically adjust dataflow to align with specific rendering metric requirements for diverse applications, effectively supporting both typical and the latest hybrid rendering pipelines. |

|
Fusion-3D: Integrated Acceleration for Instant 3D Reconstruction and Real-Time Rendering
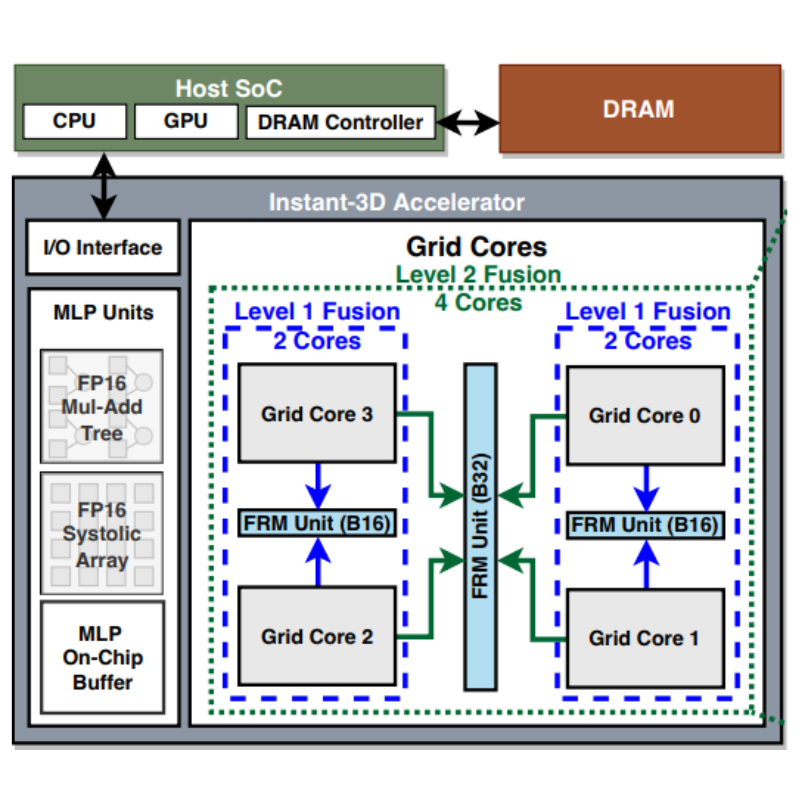
Sixu Li, Yang (Katie) Zhao, Chaojian Li, Bowei Guo, Jingqun Zhang, Wenbo Zhu, Zhifan Ye, Cheng Wan, Yingyan (Celine) Lin MICRO, 2024 Best Paper Award; My Contribution: Led Algorithm Development. Demonstrating end-to-end acceleration for emerging applications in 3D intelligence by achieving instant reconstruction and real-time rendering across diverse scene scales. |
|
Instant-3D: Instant Neural Radiance Field Training Towards On-Device AR/VR 3D Reconstruction
Sixu Li*, Chaojian Li*, Wenbo Zhu, Boyang (Tony) Yu, Yang (Katie) Zhao, Cheng Wan, Haoran You, Yingyan (Celine) Lin ISCA, 2023 Paper The first algorithm-hardware co-design acceleration framework that achieves instant on-device NeRF training. |
|
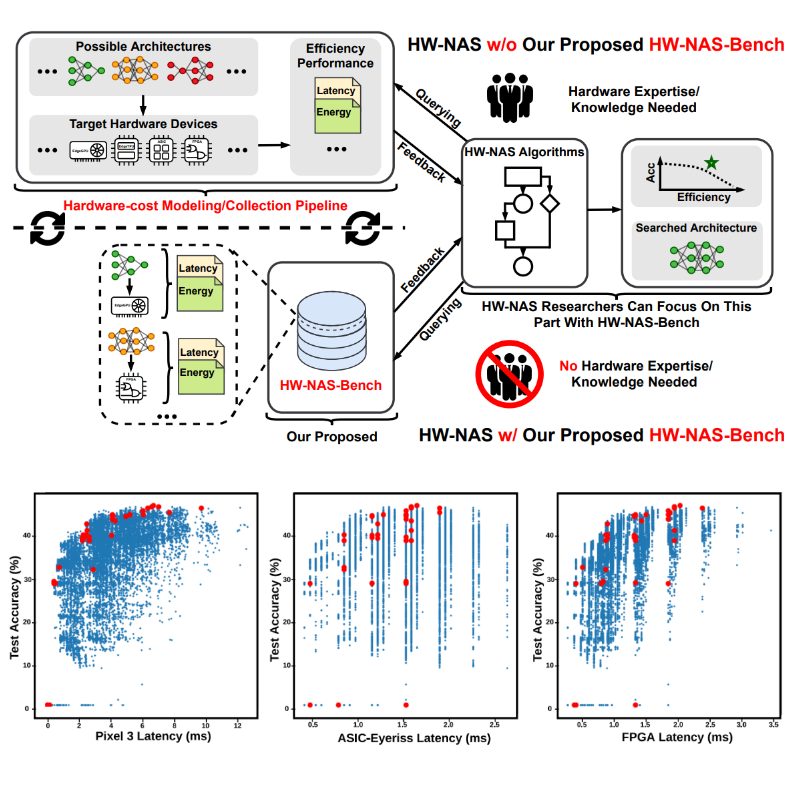
HW-NAS-Bench: Hardware-aware neural architecture search benchmark
Chaojian Li, Zhongzhi Yu, Yonggan Fu, Yongan Zhang, Yang (Katie) Zhao, Haoran You, Qixuan Yu, Yue Wang, Yingyan (Celine) Lin ICLR, 2021 Paper / Code The first public dataset for HW-NAS research aiming to (1) democratize HW-NAS research to non-hardware experts and (2) facilitate a unified benchmark for HW-NAS to make HW-NAS research more reproducible and accessible. |
|
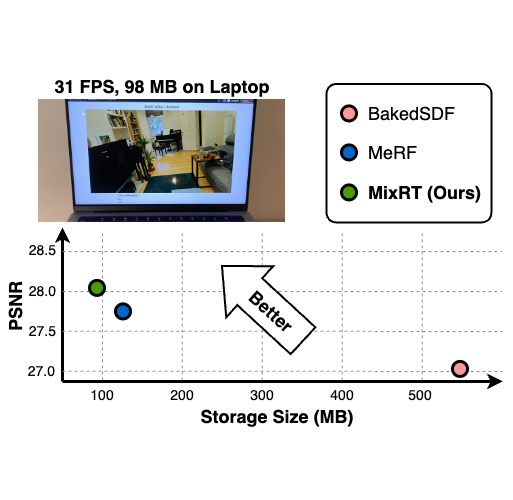
MixRT: Mixed Neural Representations For Real-Time NeRF Rendering
Chaojian Li, Bichen Wu, Peter Vajda, Yingyan (Celine) Lin 3DV, 2024 Project Page Mixing a low-quality mesh, a view-dependent-displacement map, and a compressed NeRF model to achieve real-time rendering speeds on edge devices. |
|
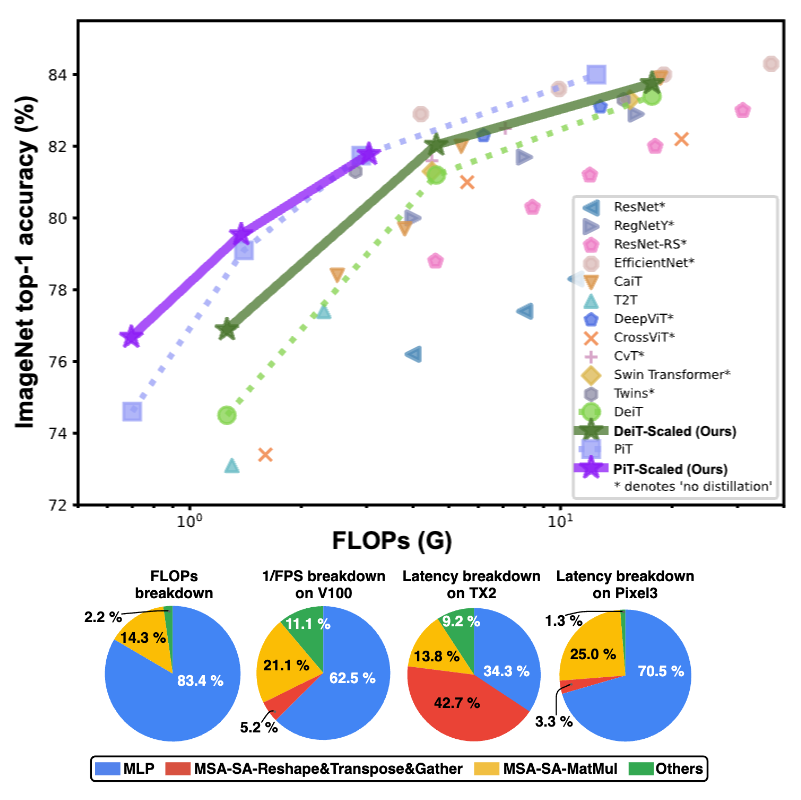
An Investigation on Hardware-Aware Vision Transformer Scaling
Chaojian Li, Kyungmin Kim, Bichen Wu, Peizhao Zhang, Hang Zhang, Xiaoliang Dai, Peter Vajda, Yingyan (Celine) Lin ACM Transactions on Embedded Computing Systems, 2023 Paper Simply scaling ViT's depth, width, input size, and other basic configurations, we show that a scaled vanilla ViT model without bells and whistles can achieve comparable or superior accuracy-efficiency trade-off than most of the latest ViT variants. |
|
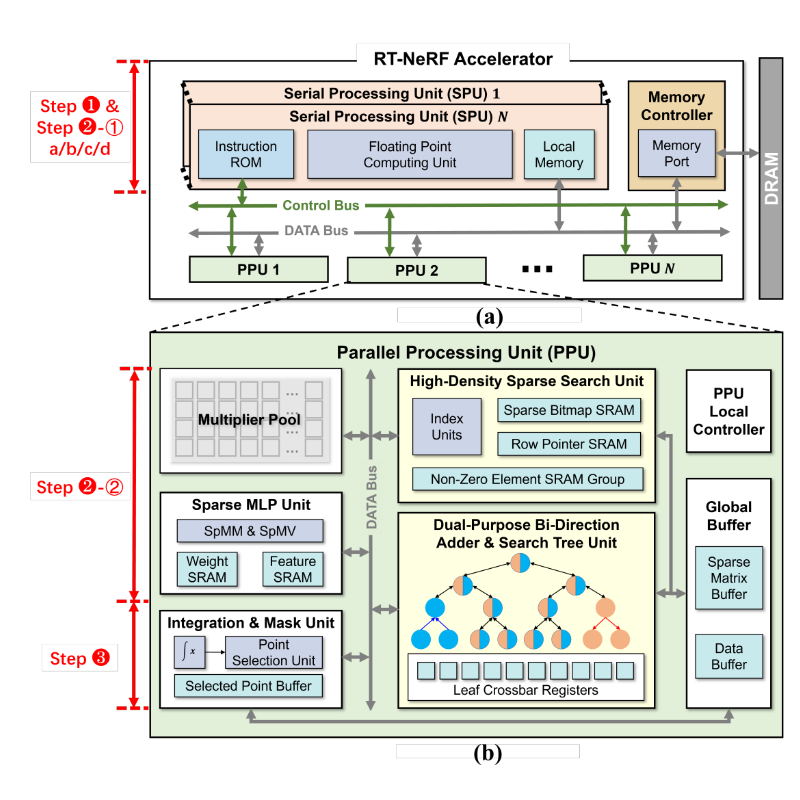
RT-NeRF: Real-Time On-Device Neural Radiance Fields Towards Immersive AR/VR Rendering
Chaojian Li*, Sixu Li*, Yang (Katie) Zhao, Wenbo Zhu, Yingyan (Celine) Lin ICCAD, 2022 Paper / Project Page The first algorithm-hardware co-design acceleration of NeRF rendering. |
|
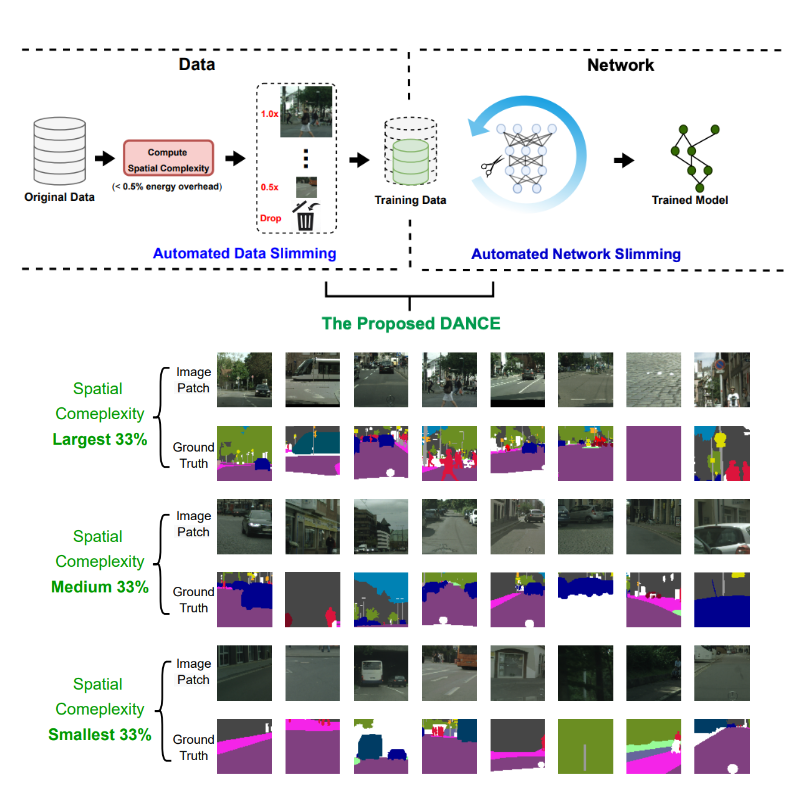
DANCE: DAta-Network Co-optimization for Efficient Segmentation Model Training and Inference
Chaojian Li, Wuyang Chen, Yuchen Gu, Tianlong Chen, Yonggan Fu, Zhangyang (Atlas) Wang, Yingyan (Celine) Lin ACM Transactions on Design Automation of Electronic Systems, 2022 Paper A framework for boosting semantic segmentation efficiency during both training and inference, leveraging the hypothesis that maximum model accuracy and efficiency should be achieved when the data and model are optimally matched. |
|
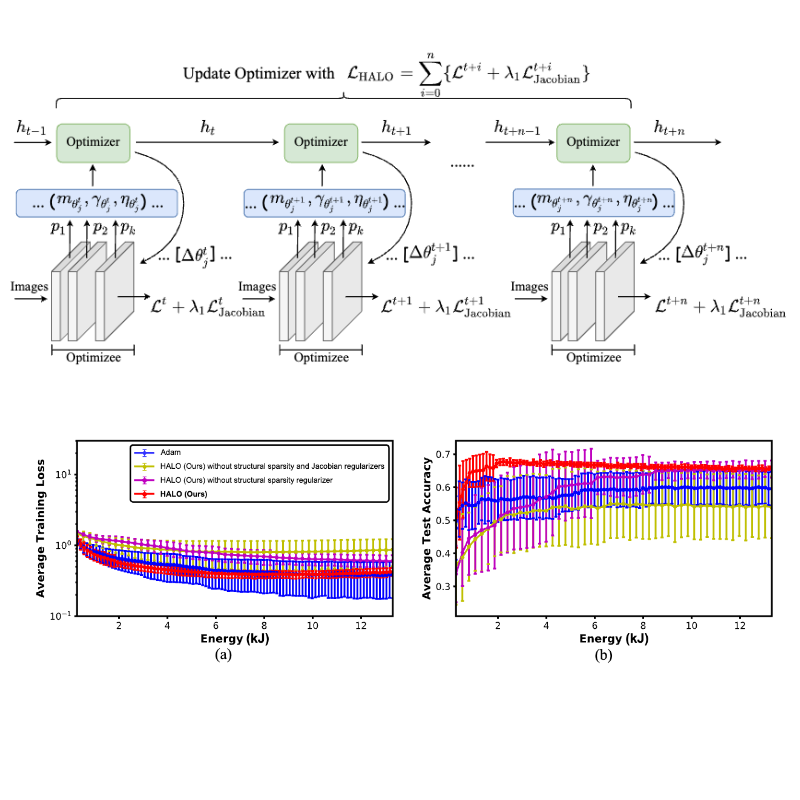
HALO: Hardware-aware learning to optimize
Chaojian Li*, Tianlong Chen*, Haoran You, Zhangyang (Atlas) Wang, Yingyan (Celine) Lin ECCV, 2020 Paper / Code A practical meta optimizer dedicated to resource-efficient on-device adaptation. |
|
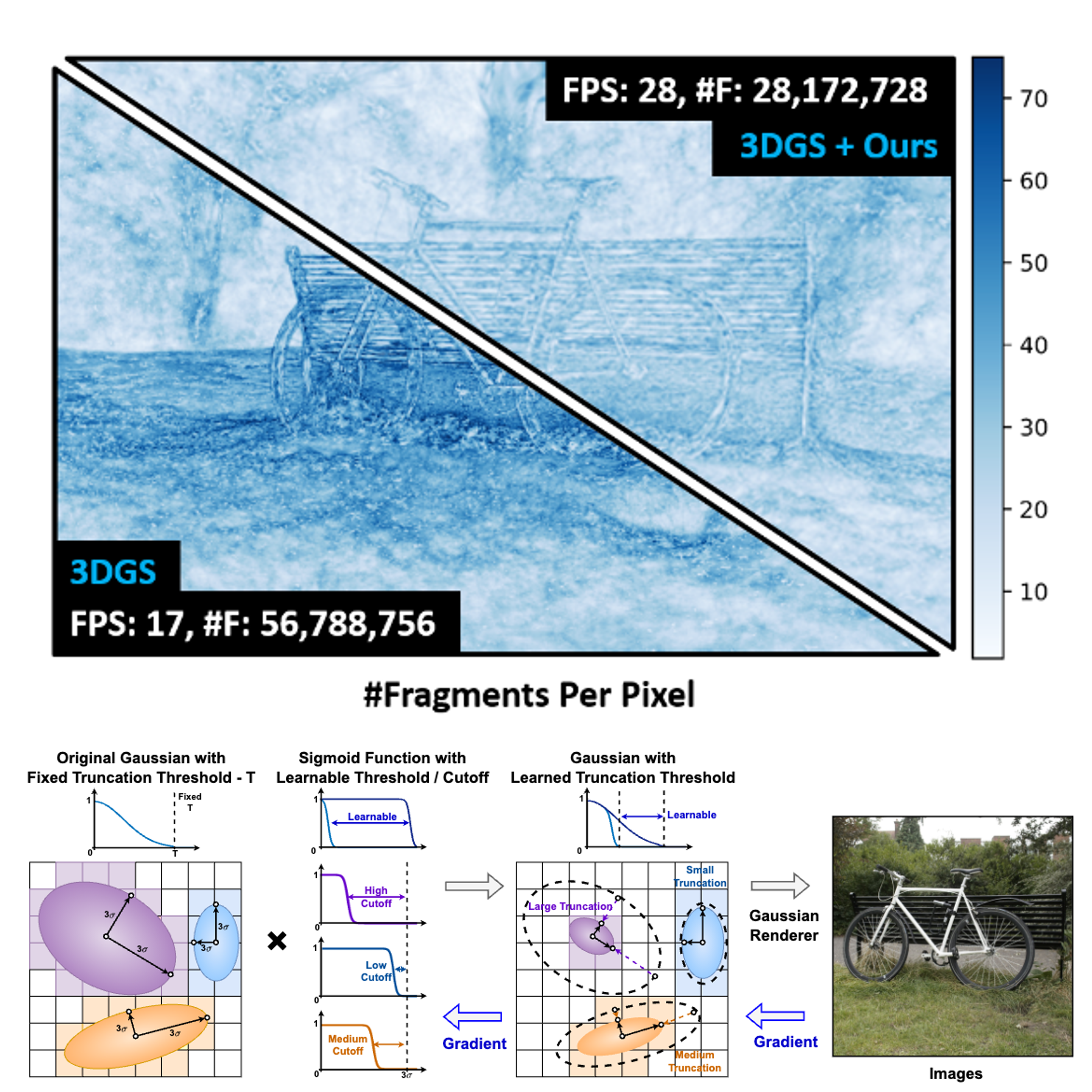
3D Gaussian Rendering Can Be Sparser: Efficient Rendering via Learned Fragment Pruning
Zhifan Ye, Chenxi Wan, Chaojian Li, Jihonn Hong, Sixu Li, Leshu Li, Yongan Zhang, Yingyan (Celine) Lin NeurIPS, 2024 An orthogonal enhancement to existing 3D Gaussian pruning methods that can significantly accelerate rendering by selectively pruning fragments within each Gaussian. |
|
Design and source code from Jon Barron's website. |